SARS-CoV-2 strategically mimics proteolytic activation of human ENaC
- nference Labs, India
- nference, Inc, United States
Abstract
Molecular mimicry is an evolutionary strategy adopted by viruses to exploit the host cellular machinery. We report that SARS-CoV-2 has evolved a unique S1/S2 cleavage site, absent in any previous coronavirus sequenced, resulting in the striking mimicry of an identical FURIN-cleavable peptide on the human epithelial sodium channel α-subunit (ENaC-α). Genetic alteration of ENaC-α causes aldosterone dysregulation in patients, highlighting that the FURIN site is critical for activation of ENaC. Single cell RNA-seq from 66 studies shows significant overlap between expression of ENaC-α and the viral receptor ACE2 in cell types linked to the cardiovascular-renal-pulmonary pathophysiology of COVID-19. Triangulating this cellular characterization with cleavage signatures of 178 proteases highlights proteolytic degeneracy wired into the SARS-CoV-2 lifecycle. Evolution of SARS-CoV-2 into a global pandemic may be driven in part by its targeted mimicry of ENaC-α, a protein critical for the homeostasis of airway surface liquid, whose misregulation is associated with respiratory conditions.
eLife digest
Viruses hijack the cellular machinery of humans to infect their cells and multiply. The virus causing the global COVID-19 pandemic, SARS-CoV-2, is no exception. Identifying which proteins in human cells the virus co-opts is crucial for developing new ways to diagnose, prevent and treat COVID-19 infections.
SARS-CoV-2 is covered in spike-shaped proteins, which the virus uses to gain entry into cells. First, the spikes bind to a protein called ACE2, which is found on the cells that line the respiratory tract and lungs. SARS-CoV-2 then exploits enzymes called proteases to cut, or cleave, its spikes at a specific site which allows the virus to infiltrate the host cell. Proteases identify which proteins to target based on the sequence of amino acids – the building blocks of proteins – at the cleavage site. However, it remained unclear which human proteases SARS-CoV-2 co-opts and whether its cut site is similar to human proteins.
Now, Anand et al. show that the spike proteins on SARS-CoV-2 may have the same sequence of amino acids at its cut site as a human epithelial channel protein called ENaC-α. This channel is important for maintaining the balance of salt and water in many organs including the lungs. Further analyses showed that ENaC-α is often found in the same types of human lung and respiratory tract cells as ACE2. This suggests that SARS-CoV-2 may use the same proteases that cut ENaC-α to get inside human respiratory cells.
It is possible that by hijacking the cutting mechanism for ENaC-α, SARS-CoV-2 interferes with the balance of salt and water in the lungs of COVID-19 patients. This may help explain why the virus causes severe respiratory symptoms. However, more studies are needed to confirm that the proteases that cut ENaC-α also cut the spike proteins on SARS-CoV-2, and how this affects the respiratory health of COVID-19 patients.
Introduction
The surface of SARS-CoV-2 virions is coated with the spike (S) glycoprotein, whose proteolysis is key to the infection lifecycle. After the initial interaction of the S-protein with the ACE2 receptor (Walls et al., 2020), host cell entry is mediated by two key proteolytic steps. The S1 subunit of the S-protein engages ACE2, and viral entry into the host cell is facilitated by proteases that catalyze S1/S2 cleavage (Belouzard et al., 2012; Belouzard et al., 2009) at Arginine-667/Serine-668 (Figure 1a). This is followed by S2’ site cleavage that is required for fusion of viral-host cell membranes (Hoffmann et al., 2020; Walls et al., 2020).
Figure 1
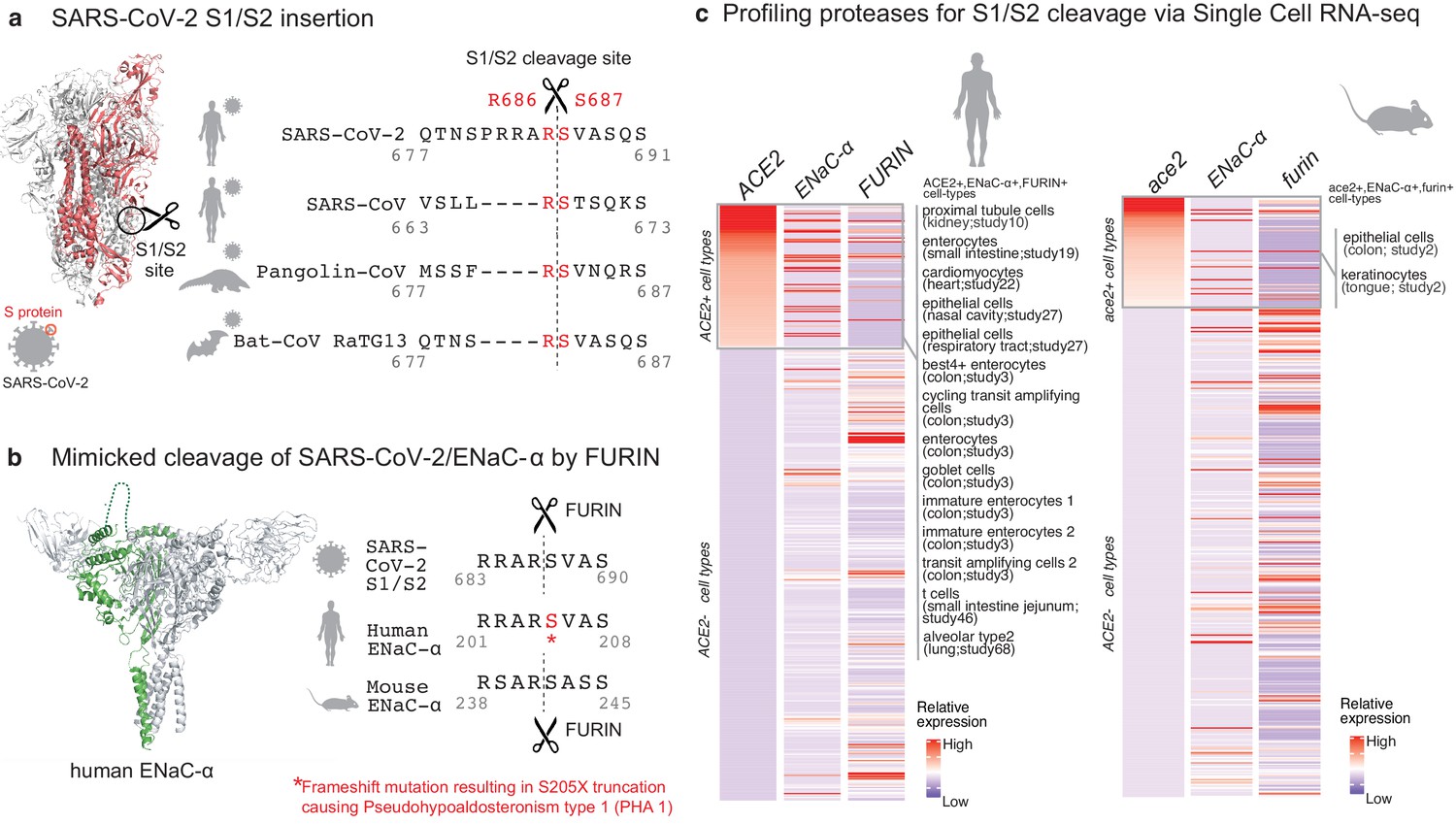
Targeted molecular mimicry by SARS-CoV-2 of human ENaC-ɑ and profiling ACE2-FURIN-ENaC-ɑ co-expression.
(a) The cartoon representation of the S-protein homotrimer from SARS-CoV-2 is shown (PDB ID: 6VSB). One of the monomers is highlighted in red. The alignment of the S1/S2 cleavage site required for the activation of SARS-CoV-2, SARS-CoV, Pangolin-CoV, and Bat-CoV RaTG13 are shown. The four amino acid insertion evolved by SARS-CoV-2, along with the abutting cleavage site is shown in a box. (b) The cartoon representation of human ENaC protein is depicted (PDB ID: 6BQN; chain in green), highlighting the ENaC-ɑ chain in green. The alignment on the right captures FURIN cleavage at the S1/S2 site of SARS-CoV-2, along with its striking molecular mimicry of the identical peptide from human ENaC-ɑ protein (dotted loop in the cartoon rendering of human ENaC). The alignment further shows the equivalent 8-mer peptide of mouse ENaC-ɑ that is also known to be cleaved by FURIN. One of the known genetic alterations on human ENaC-ɑ is highlighted as well (Welzel et al., 2013). (c) The single cell transcriptomic co-expression of ACE2, ENaC-ɑ, and FURIN is summarized. The heatmap depicts the mean relative expression of each gene across the identified cell populations. The human and mouse single cell RNA-seq are visualized independently. The cell types are ranked based on decreasing expression of ACE2. The box highlights the ACE2 positive cell types in human and mouse samples.
Results
We hypothesized that the virus may mimic host substrates to achieve proteolysis. Comparing human-infecting SARS-CoV-2 with SARS-CoV strains, as well as with candidates of zoonotic origin (Pangolin-CoV and Bat-CoV RaTG13), shows that SARS-CoV-2 has evolved a unique sequence insertion at the S1/S2 site (Zhang et al., 2020; Figure 1a). Although the S protein of SARS-CoV-2 shares high sequence identity with the S proteins of Pangolin-CoV (92%) and Bat-CoV RaTG13 (97%), the furin insertion site seems to be uniquely acquired by SARS-CoV-2. The resulting tribasic 8-mer peptide (RRARSVAS) on the SARS-CoV-2 S1/S2 site is conserved among 10,956 of 10,967 circulating strains deposited at GISAID (https://www.gisaid.org/) (Elbe and Buckland-Merrett, 2017), as of April 28, 2020 (Supplementary file 1a). This peptide is also absent in over 13,000 non-COVID-19 coronavirus S-proteins from the VIPR database (Carrillo-Tripp et al., 2009). Strikingly, examining over 10 million peptides (8-mers) of 20,350 canonical human proteins from UniProtKB shows that the peptide of interest (RRARSVAS) is present exclusively in human ENaC-ɑ, also known as SCNN1A (p-value=4E-4) (see Materials and methods). The location of this SARS-CoV-2 mimicked peptide in the ENaC-ɑ structure is in the extracellular domain (Noreng et al., 2018; Figure 1b). This suggests that the SARS-CoV-2 may have specifically evolved to mimic a human protease substrate.
ENaC regulates sodium ion (Na+) and water homeostasis, and ENaC’s expression levels are controlled by aldosterone and the associated Renin-Angiotensin-Aldosterone System (RAAS)6. In distal lung airways, ENaC is known to play a key role in controlling fluid reabsorption at the air–liquid interface (Rossier and Stutts, 2009), and similar to SARS-CoV2, ENaC-ɑ also needs to be proteolytically activated for its function (Vallet et al., 1997). FURIN cleaves the equivalent peptide on mouse ENaC-ɑ between the Arginine and Serine residues in the 4th and 5th positions respectively (RSAR|SASS) (Hughey et al., 2004a; Hughey et al., 2004b), akin to the recent report establishing FURIN cleavage at the S1/S2 site of SARS-CoV-2 (Walls et al., 2020; Figure 1b). It is conceivable that human ENaC activation may be compromised in SARS-CoV-2 infected cells, for instance by SARS-CoV-2 exploiting host FURIN for its own activation. The likely consequence would be low ENaC activity on the surface of the airways leading to compromised fluid reabsorption (Planès et al., 2010; Yurdakök, 2010), an important lung pathology in COVID-19 patients with acute respiratory distress syndrome (ARDS). Indeed, the exact mechanism of SARS-CoV-2’s potential impact of ENaC activation needs to be investigated.
Although the furin-like cleavage motifs can be found in other viruses (Coutard et al., 2020), the exact mimicry of human ENaC-ɑ cleavage site raises the specter that SARS-CoV-2 may be hijacking the protease network of ENaC-ɑ for viral activation. We asked whether there is an overlap between putative SARS-CoV-2 infecting cells and ENaC-ɑ expressing cells. Systematic single cell expression profiling of the ACE2 receptor and ENaC-ɑ was performed across human and mouse samples comprising ~1.3 million cells (Venkatakrishnan et al., 2020; Figure 1c). Interestingly, ENaC-ɑ is expressed in the nasal epithelial cells, type II alveolar cells of the lungs, tongue keratinocytes, and colon enterocytes (Figure 1c and Figure 2—figure supplements 1–6), which are all implicated in COVID-19 pathophysiology (Shweta et al., 2020; Venkatakrishnan et al., 2020). Further, ACE2 and ENaC-ɑ are known to be expressed generally in the apical membranes of polarized epithelial cells (Butterworth, 2010; Musante et al., 2019). The overlap of the cell-types expressing ACE2 and ENaC-ɑ, and similar spatial distributions at the apical surfaces, suggest that SARS-CoV-2 may be leveraging the protease network responsible for ENaC cleavage.
Beyond FURIN, which cleaves the S1/S2 site (Walls et al., 2020), we were intrigued by the possibility of other host proteases also being exploited by SARS-CoV-2. We created a 160-dimensional vector space (20 amino acids x eight positions on the peptide) for assessment of cleavage similarities between the 178 human proteases with biochemical validation from the MEROPS database (see Materials and methods; 0 < protease similarity metric <1) (Rawlings et al., 2018). This shows that FURIN (PCSK3) has overall proteolytic similarity to select PCSK family members, specifically PCSK5 (0.99), PCSK7 (0.99), PCSK6 (0.99), PCSK4 (0.98), and PCSK2 (0.94) (Supplementary file 1b). It is also known that the protease PLG cleaves the ɣ-subunit of ENaC (ENaC-ɣ)(Passero et al., 2008).
In order to extrapolate the tissue tropism of SARS-CoV-2 from the lens of the host proteolytic network, we assessed the co-expression of these proteases concomitant with the viral receptor ACE2 and ENaC-ɑ (Figure 2). This analysis shows that FURIN is expressed with ACE2 and ENaC-ɑ in the colon (immature enterocytes, transit amplifying cells) and pancreas (ductal cells, acinar cells) of human tissues, as well as tongue (keratinocytes) of mouse tissues. PCSK5 and PCSK7 are broadly expressed across multiple cell types with ACE2 and ENaC-ɑ, making it a plausible broad-spectrum protease that may cleave the S1/S2 site. In humans, concomitant with ACE2 and ENaC-ɑ, PCSK6 appears to be expressed in cells from the intestines, pancreas, and lungs, whereas PCSK2 is noted to be co-expressed in the pancreas (Figure 2). It is worth noting that the extracellular proteases need not necessarily be expressed in the same cells as ACE2 and ENaC-ɑ. Among the PCSK family members with the potential to cleave the mimicked 8-mer peptide, it is intriguing that the same tissue can house multiple proteases and also that multiple tissues do share the same set of proteases.
Figure 2 with 6 supplements see all
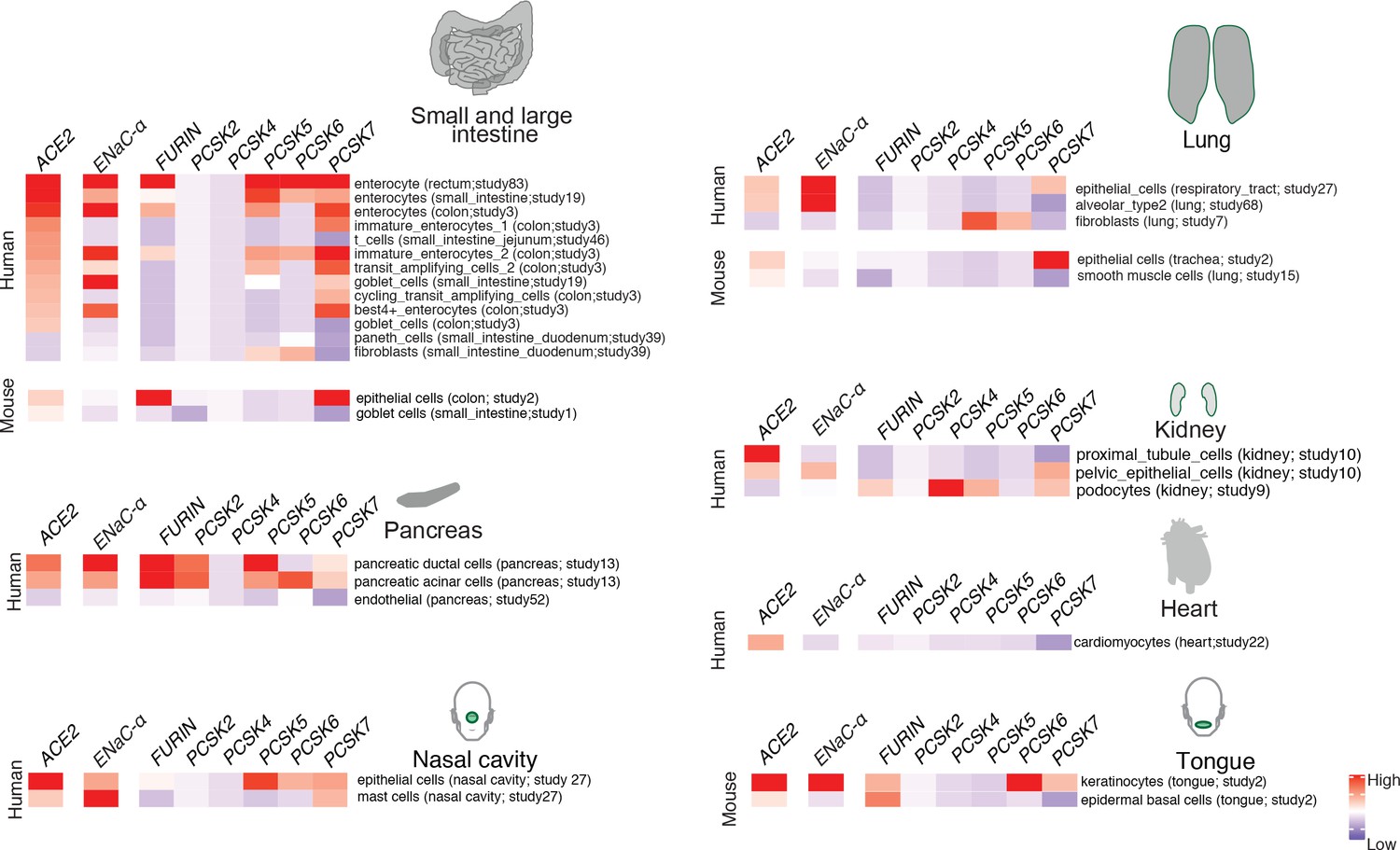
Expression profiling of identified proteases.
The heatmap depicts the relative expression of ACE2 and ENaC-ɑ along with a list of proteases that can potentially cleave the S1/S2 site. The relative expression levels are denoted on a scale of blue (low) to red (high). The rows denote proteases and columns denote cell-types.
Discussion
Our findings emphasize that redundancy may be wired into the mechanisms of host proteolytic activation of SARS-CoV-2. This study should stimulate the design of experiments that confirm the working hypothesis generated by our unbiased and systematic computational analysis. The mimicry of a cleavable host peptide central to pulmonary, renal, and cardiovascular function provides a new perspective to the evolution of SARS-CoV-2 in causing a global coronavirus pandemic.
Materials and methods
Alignment of coronavirus spike proteins
Request a detailed protocolThe complete S-protein sequence for SARS-CoV (Uniprot ID: P59594) and SARS-CoV-2 was obtained from uniprot (ftp://ftp.uniprot.org/pub/databases/uniprot/pre_release/). The sequences of Pangolin-CoV and Bat-CoV RaTG13 were obtained from the VIPR database (https://www.viprbrc.org/). Sequence alignments using Clustal-W, and comparison of SARS-CoV-2 versus other coronavirus strains were performed using JalView17.
Analysis of 8-mers of the human proteome
Request a detailed protocolWe enumerated 10,257,893 (10.26M) 8-mers from 20,350 reviewed uniprot reference sequences from human proteome (Proteome ID: UP000005640, as accessed on May 4th 2020). The previously identified SARS-CoV-2 8-mer ‘RRARSVAS’ was in fact found in ENaC-ɑ protein (Uniprot ID: P37088; p-value ≈ 10.26M/208 = 4E-4; chance of finding that particular 8-mer anywhere in the reference sequences).
Calculating the cosine similarity metric for protease cleavage site
Request a detailed protocolThe position frequency matrix (PFM) of the individual proteases obtained from the MEROPS database (Rawlings et al., 2018) was converted to a probability weight matrix (PWM) (normalized and scaled) (Supplementary file 1b). Out of 178 proteases, there were 146 proteases that had specificity information available on the eight mer peptide spanning the cleavage site (±4). The 20 (amino acids) x 8 (position) matrix defined for each of the proteases were flattened into a single vector with 160 elements. We performed a cosine similarity calculation between all pairs (X,Y) of protease specificity vector. The similarity was derived as the normalized dot product of X and Y: K(X, Y) = <X, Y> / (||X||*||Y||)).
Overlap of cell types expressing ENaC-ɑ, ACE2, and proteases from scRNA-seq datasets
Request a detailed protocolWe performed a systematic expression profiling of the ACE2 and ENaC-ɑ across 65 published human and mouse single-cell studies comprising ~1.3 million cells using nferX Single Cell platform (Supplementary file 1c, https://academia.nferx.com/) (Venkatakrishnan et al., 2020). The ACE2 expression could be detected in 66 studies (59 studies of human samples and 7 studies of mouse samples) spanning across ~50 tissues, over 450 cell-types and ~1.05 million cells. In order to call a given cell-type to be positive for both ACE2 and a protease we applied a cutoff of 1% of the cells in the total cell-type cluster population to have a non-zero count associated with both ACE2 and the respective protease. The mean expression of the proteases, ENaC-ɑ and ACE2 was derived for individual cell population within each of the studies. The cell-type information was obtained from the author annotations provided for each of the studies. The analysis was performed separately on the mouse and human datasets. For each protease, the mean expression of given cell-population (mean log[cp10k +1] counts) was Z-score normalized (to ensure the sd = 1 and mean ~0 for all the genes) to obtain relative expression profiles across all the samples. The same normalization was applied to ACE2 and ENaC-ɑ and both human and mouse datasets were analyzed independently by generating heatmaps. The cell types having zero-expression values of ACE2 were also included as negative control to probe the expression of various proteases.
We performed an analysis to identify the cell types with significant overlap of ACE2 and ENaC-ɑ expression. To this end, we shortlisted cell types in which ENaC-ɑ is expressed in a significantly higher proportion of ACE2-expressing cells than in the overall population of cells of that sub-type. We computed the ratios of these proportions, and used a corresponding Fisher exact test to compute significance.
Data availability
All data generated or analysed during this study are included in the manuscript and supporting files.
References
-
Regulation of the epithelial sodium channel (ENaC) by membrane traffickingBiochimica Et Biophysica Acta (BBA) - Molecular Basis of Disease 1802:1166–1177.https://doi.org/10.1016/j.bbadis.2010.03.010
-
VIPERdb2: an enhanced and web API enabled relational database for structural virologyNucleic Acids Research 37:D436–D442.https://doi.org/10.1093/nar/gkn840
-
Epithelial sodium channels are activated by furin-dependent proteolysisJournal of Biological Chemistry 279:18111–18114.https://doi.org/10.1074/jbc.C400080200
-
Distinct pools of epithelial sodium channels are expressed at the plasma membraneJournal of Biological Chemistry 279:48491–48494.https://doi.org/10.1074/jbc.C400460200
-
Plasmin activates epithelial na+ channels by cleaving the gamma subunitThe Journal of Biological Chemistry 283:36586–36591.https://doi.org/10.1074/jbc.M805676200
-
Activation of the epithelial sodium channel (ENaC) by serine proteasesAnnual Review of Physiology 71:361–379.https://doi.org/10.1146/annurev.physiol.010908.163108
-
Five novel mutations in the SCNN1A gene causing autosomal recessive pseudohypoaldosteronism type 1European Journal of Endocrinology 168:707–715.https://doi.org/10.1530/EJE-12-1000
-
Transient tachypnea of the newborn: what is new?The Journal of Maternal-Fetal & Neonatal Medicine 23 Suppl 3:24–26.https://doi.org/10.3109/14767058.2010.507971
Article and author information
Author details
AJ Venkatakrishnan

Venky Soundararajan
Funding
The authors declare that there was no external funding for this work.
Acknowledgements
The authors thank Patrick Lenehan, David Zemmour, Travis Hughes, Tyler Wagner, and Mathai Mammen for their careful review and feedback. The authors are also grateful to Ramakrishna Chilaka for the software visualization tools, and Dhruti Patwardhan, Saranya Marimuthu, Jaya Jain, Dariusz Murakowski, and Enrique Garcia-Rivera for their assistance with databases.
Version history
- Received: May 5, 2020
- Accepted: May 25, 2020
- Accepted Manuscript published: May 26, 2020 (version 1)
- Version of Record published: July 8, 2020 (version 2)
Copyright
© 2020, Anand et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 20,316
- views
-
- 2,399
- downloads
-
- 106
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
SARS-CoV-2 strategically mimics proteolytic activation of human ENaC
eLife 9:e58603.
https://doi.org/10.7554/eLife.58603
Further reading
-
- Computational and Systems Biology
- Developmental Biology
Organisms utilize gene regulatory networks (GRN) to make fate decisions, but the regulatory mechanisms of transcription factors (TF) in GRNs are exceedingly intricate. A longstanding question in this field is how these tangled interactions synergistically contribute to decision-making procedures. To comprehensively understand the role of regulatory logic in cell fate decisions, we constructed a logic-incorporated GRN model and examined its behavior under two distinct driving forces (noise-driven and signal-driven). Under the noise-driven mode, we distilled the relationship among fate bias, regulatory logic, and noise profile. Under the signal-driven mode, we bridged regulatory logic and progression-accuracy trade-off, and uncovered distinctive trajectories of reprogramming influenced by logic motifs. In differentiation, we characterized a special logic-dependent priming stage by the solution landscape. Finally, we applied our findings to decipher three biological instances: hematopoiesis, embryogenesis, and trans-differentiation. Orthogonal to the classical analysis of expression profile, we harnessed noise patterns to construct the GRN corresponding to fate transition. Our work presents a generalizable framework for top-down fate-decision studies and a practical approach to the taxonomy of cell fate decisions.
-
- Computational and Systems Biology
- Genetics and Genomics
We propose a new framework for human genetic association studies: at each locus, a deep learning model (in this study, Sei) is used to calculate the functional genomic activity score for two haplotypes per individual. This score, defined as the Haplotype Function Score (HFS), replaces the original genotype in association studies. Applying the HFS framework to 14 complex traits in the UK Biobank, we identified 3619 independent HFS–trait associations with a significance of p < 5 × 10−8. Fine-mapping revealed 2699 causal associations, corresponding to a median increase of 63 causal findings per trait compared with single-nucleotide polymorphism (SNP)-based analysis. HFS-based enrichment analysis uncovered 727 pathway–trait associations and 153 tissue–trait associations with strong biological interpretability, including ‘circadian pathway-chronotype’ and ‘arachidonic acid-intelligence’. Lastly, we applied least absolute shrinkage and selection operator (LASSO) regression to integrate HFS prediction score with SNP-based polygenic risk scores, which showed an improvement of 16.1–39.8% in cross-ancestry polygenic prediction. We concluded that HFS is a promising strategy for understanding the genetic basis of human complex traits.




{kind=link}
{kind=link}